sed 简要介绍
Sed(Stream EDitor)为 UNIX 系统上提供将编辑工作自动化的编辑器 , 使用者无需直接编辑资料。使用者可利用 sed 所提供 20 多种不同的函数[参数] , 组合它们完成不同的编辑动作。此外 ,由於 sed 都以行为单位编辑文件 , 故其亦是行编辑器(line editor)。
一般 sed 最常用在编辑那些需要不断重覆某些编辑动作的文件上, 例如将文件中的某个字串替换成另一个字串等等。这些相较於一般 UNIX 编辑器(交互式的, 如 vi、emacs)用手动的方式修改文件, sed 用起来较省力。
sed 是一个非交互式上下文(context)编辑器,它被设计在下列三种情况下发挥作用:
- 编辑那些对舒适的交互式编辑而言太大的文件。
- 在编辑命令太复杂而难于在交互模式下键入的时候,编辑任何大小的文件。
- 要在对输入的一趟扫描中有效的进行多个”全局”(global)编辑函数。
因为每次只把输入的某些行驻留在内存中, 并且不使用临时文件,所以可编辑的文件的有效大小,只受限于输入和输出要同时共存于次级存储的要求。可以单独的建立复杂的编辑脚本并作为给 sed 的命令文件。对于复杂的编辑,这节省了可观的键入和随之而来的错误。从命令文件运行 sed 高效于作者所知道的任何交互式编辑器,甚至包括能用预先写好的脚本驱动的编辑器。
相较于交互式编辑器而言,根本性的损失是缺乏相对地址(由于操作是每次一行的),和缺乏对命令如期运行的立即验证。
sed 如何工作
如同其它 UNIX 命令, sed 由标准输入读入编辑文件并由标准输出送出结果。下图表示 sed将资料行 “Unix“ 替换成 “UNIX“,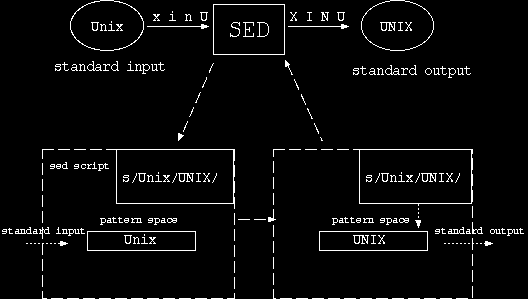
在图中, 上方 standard input 为标准输入, 是读取资料之处; standard output 为标准输出, 是送出结果之处;中间 sed 方块的下面两个虚线方块表示 sed 的工作流程。其中, 左边虚线方块表示 sed 将标准输入资料置入pattern space, 右边虚线方块表示 sed 将 pattern space 中编辑完毕後的资料送到标准输出。
在虚线方块中, 两个实线方块分别表示 pattern space 与 sed script。其中, pattern space 为一缓区, 它是sed 工作场所; 而 sed script 则表示一组执行的编辑指令。
在图中, 左边虚线方块 “Unix” 由标准输入置入 pattern space; 接着 , 在右边虚线方块中, sed执行 sed script 中的编辑指令s/Unix/UNIX/, 结果 “Unix” 被替换成 “UNIX”, 之後, “UNIX” 由pattern space 送到标准输出。
总合上述所言, 当 sed 由标准输入读入一行资料并放入 pattern space 时, sed 依照 sed script 的编辑指令逐一对 pattern space 内的资料执行编辑, 之後, 再由 pattern space 内的结果送到标准输出, 接着再将下一行资料读入。如此重复执行上述动作 , 直至读完所有资料行为止。
sed 维护一种模式空间(patter space),即一个工作区或临时缓冲区,当应用编辑命令时将在那里存储单个输入行。sed 还维护了称为保持空间(hold space)的另一个临时缓冲区,可以将模式空间的内容复制到保持空间并在以后检索它们。
使用 sed
sed 命令列可分成编辑指令与文件档部份。其中, 编辑指令负责控制所有的编辑工作; 文件档表示所处理的档案。sed 的编辑指令均由位址(address)与函数(function)两部份组成, 其中, 在执行时, sed 利用它的位址参数来决定编辑的对象; 而用它的函数[参数]编辑。
此外, sed 编辑指令, 除了可在命令列上执行, 也可在档案内执行。其中差别只是在命令列上执行时, 其前必须加上选项 -e; 而在档案内时, 则只需在其档名前加上选项 -f。另外, sed 执行编辑指令是依照它们在命令列上或档内的次序。
下面各节, 将介绍执行命令列上的编辑指令、sed 编辑指令、执行档案内的编辑指令、执行多个档案的编辑、及执行 sed 输出控制。
执行命令列上的编辑指令
当编辑指令在命令列上执行时, 其前必须加上选项 -e 。其命令格式如下:
其中, 所有编辑指令都紧接在选项 -e 之後, 并置於两个 “'“ 特殊字元间。另外, 命令上编辑指令的执行是由左而右。
一般编辑指令不多时, 使用者通常直接在命令上执行它们。例如, 删除 yel.dat 内 1 至10 行资料 , 并将其馀文字中的 “yellow“ 字串改成 “black“ 字串。此时 , 可将编辑指令直接在命令上执行 , 其命令如下 :
在命令中 , 编辑指令 ‘1,10d‘ 执行删除 1 至 10 行资料 ; 编辑指令 ‘s/yellow/black/g‘,”yellow“ 字串替换(substitute)成 “black“ 字串。
sed 的编辑指令
sed 编辑指令的格式如下 :
其中 , 位址参数 address1 、address2 为行数或 regular expression 字串 , 表示所执行编辑的资料行 ; 函数参数 function[argument] 为 sed 的内定函数 , 表示执行的编辑动作。
下面两小节 , 将仔细介绍位址参数的表示法与有哪些函数参数供选择。
位址(address)参数的表示法
实际上 , 位址参数表示法只是将要编辑的资料行 , 用它们的行数或其中的字串来代替表示它们。下面举几个例子说明(指令都以函数参数 d 为例) :
- 删除档内第 10 行资料 , 则指令为
10d - 删除含有 “man” 字串的资料行时 , 则指令为
/man/d - 删除档内第 10 行到第 200 行资料, 则指令为
10,200d - 删除档内第 10 行到含 “man” 字串的资料行 , 则指令为
10,/man/d
接下来 , 以位址参数的内容与其个数两点 , 完整说明指令中位址参数的表示法(同样也以函数参数 d 为例)。
位址参数的内容:
- 位址为十进位数字 (行地址): 此数字表示行号。当指令执行时 , 将对符合此行号的资料执行函数参数指示的编辑动作。例如 ,删除资料档中的第 15 行资料 , 则指令为
15d。其馀类推 ,如删除资料档中的第 m 行资料 , 则指令为md。行号是由 sed 维护的内部行数。该计数器不会因为多个输入文件而重置。因此,不管指定多少个输入文件,在输入流(多个文件(流)构成一个输入流,文件个数不同,输入流的大小也会不同)中也只有一行1。同样,输入流也只有一个最后的行。可以使用寻址符号$指定。下面的示例删除输入流的最后一行:$d($符号不应该和正则表达式中使用的$相混淆,在这里表示行的结束) - 位址为 regular expression(模式地址): 当资料行中有符合 regular expression 所表示的字串时 , 则执行函数参数指示的编辑动作。另外 ,在regular expression 前後必须加上 “
/“。例如指令为/t.*t/d, 表示删除所有含两 “t“ 字母的资料行。其中 , “.“表示任意字元; “*“ 表示其前字元可重复任意次 , 它们结合 “.*“ 表示两 “t“ 字母间的任意字串。
- 位址为十进位数字 (行地址): 此数字表示行号。当指令执行时 , 将对符合此行号的资料执行函数参数指示的编辑动作。例如 ,删除资料档中的第 15 行资料 , 则指令为
位址参数的个数 : 在指令中 , 如果没有指定位址参数 , 表示全部资料行执行函数参数所指示的编辑动作; 如果只有一位址参数 , 表示只有符合位址的资料行才编辑 ; 如果指定了由逗号分隔的两个位址参数 , 如
address1,address2时 ,表示对资料区执行编辑 ,address1代表起始资料行 ,address2代表结束资料行(即编辑命令应用于第一个地址的第一行和它后面的行,直到匹配第二个地址的行(包括此行)。你可以把第一个地址看做是启用动作,并把第二个地址看做是禁用动作。sed 没有办法先行决定第二个地址是否会匹配。一旦匹配了第一个地址,这个(些)动作就将应用于这些行。于是编辑命令应用于“所有”随后的行直到第二个地址被匹配。)。如果地址后面跟有感叹号(!),那么编辑命令就应用于不匹配该地址的所有的行。对於上述内容 , 以下面例子做具体说明。- 例如指令为
d其表示删除档内所有资料行。 - 例如指令为
5d其表示删除档内第五行资料。 - 例如指令为
1,/apple/d其表示删除资料区 , 由档内第一行至内有 “apple“ 字串的资料行。 - 例如指令为
/apple/,/orange/d其表示删除资料区 , 由档内含有 “apple“ 字串至含有 “orange“ 字串的资料行 - 例如指令为
/regular/!d其表示删除所有的不包含“regular”字符串的资料行。
- 例如指令为
有哪些函数(function)参数
下表中介绍所有 sed 的函数参数的功能。
| 函数参数 | 功能 |
|---|---|
| :label | 建立script file内指令互相参考的位置 |
| # | 建立注解 |
| { } | 集合有相同位址参数的指令 |
| ! | 不执行函数参数 |
| = | 印出资料行数(line number) |
| a\ | 添加使用者输入的资料 |
| b label | 将执行的指令跳至由 : 建立的参考位置 |
| c\ | 以使用者输入的资料取代资料 |
| d | 删除资料 |
| D | 删除 pattern space 内第一个 newline 字母 \n 前的资料 |
| g | 从 hold space 中拷贝资料 |
| G | 拷贝 hold space 中的资料添加到 pattern space |
| h | 从 pattern space 中拷贝资料到 hold space |
| H | 拷贝 pattern space 中的资料添加到 hold space |
| I | 印出资料中的 nonprinting character 的ASCII码值 |
| i\ | 插入添加使用者输入的资料行 |
| n | 读入下一笔资料 |
| N | 添加下一笔资料到 pattern space |
| p | 印出资料 |
| P | 印出 pattern space 内第一个 newline 字母 \n 前的资料 |
| q | 跳出 sed 编辑 |
| r | 读入文档内容 |
| s | 替换字串 |
| t label | 先执行一替换编辑命令,如果替换成功,则将编辑指令跳至 :label 处执行 |
| w | 写资料到文档 |
| x | 交换 hold space 与 pattern space 中的内容 |
| y | 转换(transform)字元 |
虽然 , sed 只有上表所述几个拥有基本编辑功能的函数 , 但由指令中位址参数和指令与指令间的配合 , 也能使sed 完成大部份的编辑任务。
执行档案内的编辑指令
当执行的指令太多 , 在命令列上撰写起来十分混乱 , 此时 , 可将这些指令整理储存在档案 (譬如档名为 script_file )内 , 用选项 -f script_file , 则让 sed 执行 script_file 内的编辑指令。其命令的格示如下 :
其中 , 执行 script_file 内编辑指令的顺序是由上而下。例如上一节的例子 , 其可改成如下命令:
其中 , ysb.scr 档的内容如下 :
另外 , 在命令列上可混合使用选项 -e 与 -f , sed 执行指令顺序依然是由命令列的左到右,如执行至 -f 後档案内的指令 , 则由上而下执行。
执行多个文件档的编辑
在 sed 命令列上 , 一次可执行编辑多个文件档 , 它们跟在编辑指令之後。例如 , 替换 white.dat、red.dat、black.dat 档内的 “yellow“ 字串成 “blue“ , 其命令如下:
上述命令执行时 , sed 依 white.dat、red.dat、black.dat 顺序 , 执行编辑指令 s/yellow/blue/ ,进行字串的替换。
执行输出的控制
在命令列上的选项 -n 表示输出由编辑指令控制。由前章内容得知 , sed 会 “自动的”将资料由 pattern space 输送到标准输出档。但藉着选项 -n , 可将 sed 这 “自动的” 的动作改成 “被动的” 由它所执行的编辑指令来决定结果是否输出。
由上述可知 , 选项 -n 必须与编辑指令一起配合 , 否则无法获得结果。例如 , 印出white.dat档内含有 “white“ 字串的资料行 , 其命令如下:
上面命令中 , 选项 -n 与编辑指令 /white/p 一起配合控制输出。其中 ,选项 -n 将输出控制权移给编辑指令;/white/p 将资料行中含有 “white“ 字串印出萤幕。
范例
一般在实际使用编辑器的过程中 , 常需要执行替换文件中的字串、搬移、删除、与搜寻资料行等等动作。当然 , 一般交谈式编辑器(如 vi、emacs)都能做得到上述功能 , 但文件一旦有大量上述编辑需求时 , 则用它们编辑十分没有效率。本章将用举例的方式说明如何用 sed 自动执行这些编辑功能。此外 , 在本章范例中 , 均以下述方式描述文件的需求 :
将文件中…资料 , 执行…(动作)
如此 , 目的是为了能将它们迅速的转成编辑指令。其中 , “...资料“ 部份 , 转成指令中的位址参数表示 ;”执行...动作“ 部份 , 则转成函数参数表示 。另外 ,将一个地址嵌套在另一个地址中(内层地址必须在外层地址的作用范围之内),或者 “执行…动作” 要由数个函数参数表示时, 则可利用 “{“与 “}“ 集合这些函数参数(注:左大括号必须在行末,而且右大括号本身必须单独占一行。要确保在大括号之后没有空格。), 其指令形式如下 :
上述指令表示 , 将对符合位址参数的资料 , 依次执行函数参数 1、函数参数 2、函数参数 3 … 表示的动作。
下面各节 , 分别举例说明 sed 替换资料、移动、删除资料、及搜寻资料的命令。
替换文件中的资料
sed 可替换文件中的字串、资料行、甚至资料区。其中 , 表示替换字串的指令中的函数参数为 s ;表示替换资料行、或资料区的指令中的函数参数为 c 。上述情况以下面三个例子说明。
例一. 将文件中含 “machine“ 字串的资料行中的 “phi“ 字串 , 替换成为 “beta“ 字串。其命令列如下 :
例二. 将文件中第 5 行资料 , 替换成句子 “Those who in quarrels interpose, must often wipe a bloody nose.”。其命令列如下
例三. 将文件中 1 至 100 行的资料区 , 替换成如下两行资料 :
则其命令列如下
搬动文件中的资料
使用者可用 sed 中的 hold space 暂存编辑中的资料、用函数参数 w 将文件资料搬动到它档内储存、或用函数参数 r 将它档内容搬到文件内。Hold space 是 sed 用来暂存 pattern space 内资料的暂存器 , 当 sed 执行函数参数h、H 时 , 会将 pattern space 资料暂存到 hold space ;当执行函数参数x、g、G 时 , 会将暂存的资料取到 pattern space 。下面举三个例子说明。
例一. 将文件中的前 100 资料 , 搬到文件中第 300 後输出。其命令列如下 :
mov.scr 档的内容为
其中 ,
它表示将文件中的前 100 资料 , 先储存在 hold space 之後删除 ;指令 300G 表示 , 将 hold space 内的资料 , 添加在文件中的第 300 行资料後输出。
例二. 将文件中含 “phi“ 字串的资料行 , 搬至 mach.inf 档中储存。其命令列如下 :
例三. 将 mach.inf 档内容 , 搬至文件中含 “beta“ 字串的资料行。其命令列如下 :
另外 , 由於 sed 是一 stream 编辑器 , 故理论上输出後的文件资料不可能再搬回来编辑。
删除文件中的资料
因为 sed 是一行编辑器 , 所以 sed 很容易删除个别资料行或整个资料区。一般用函数参数 d 或 D 来表示。下面举两个例子说明。
将文件内所有空白行全部删除。其命令列为
1sed -e '/^$/d' 文件档regular expression
^$表示空白行。 其中 ,^限制其後字串必须在行首;$限制其前字串必须在行尾。将文件内连续的空白行 , 删除它们成为一行。其命令列为
1234sed -e '/^$/{N/^$/D}' 文件档其中 , 函数参数
N表示 , 将空白行的下一行资料添加至 pattern space 内。函数参数/^$/D表示 ,当添加的是空白行时 , 删除第一行空白行 , 而且剩下的空白行则再重新执行指令一次。指令重新执行一次 , 删除一行空白行 ,如此反覆直至空白行後添加的为非空白行为止 , 故连续的空白行最後只剩一空白行被输出。
搜寻文件中的资料
sed 可以执行类似 UNIX 命令 grep 的功能。理论上 , 可用 regular expression 。例如 , 将文件中含有 “gamma“ 字串的资料行输出。则其命令列如下:
但是 , sed 是行编辑器 , 它的搜寻基本上是以一行为单位。因此 , 当一些字串因换行而被拆成两部份时 , 一般的方法则不可行。此时 , 就必须以合两行的方式来搜寻这些资料。其情况如下面例子:
例. 将文件中含 “omega“ 字串的资料输出。其命令列如下
gp.scr 档的内容如下 :
在上述 sed script , 因藉着函数参数 b 形成类似 C 语言中的 case statement 结构 , 使得 sed 可分别处理当资料内含 “omega“ 字串 ; 当 “omega“ 字串被拆成两行 ; 以及资料内没有”omega“ 字串的情况。接下来就依上述的三种情况 , 将 sed script 分成下面三部份来讨论。
当资料内含 “
omega“ , 则执行编辑指令1/omega/b它表示当资料内含 “
omega“ 字串时 , sed 不用再对它执行後面的指令 , 而直接将它输出。当资料内没有”
omega“ , 则执行编辑指令如下1234Nhs/.*n///omega/b其中 , 函数参数
N, 它表示将下一行资料读入使得 pattern space 内含前後两行资料 。函数参数h, 它表示将 pattern space 内的前後两行资料存入 hold space 。函数参数s/.*n//, 它表示将 pattern space 内的前後两行资料合成一行。/omega/b, 它表示如果合後的资料内含 “omega“ 字串 , 则不用再执行它之後的指令 , 而将此资料自动输出 。当合并後的资料依旧不含 “
omega“ , 则执行编辑指令如下12gD其中 , 函数参数
g, 它表示将 hold space 内合前的两行资料放回 pattern space。 函数参数D, 它表示删除两行资料中的第一行资料 , 并让剩下的那行资料 , 重新执行 sed script 。如此 ,无论是资料行内或行间的字串才可搜寻完全。