本章以stream(区别开STREAMS)为中心,讲解了UNIX的标准I/O库。
stream的核心是FILE结构。打开一个stream时,fopen返回一个FILE对象指针。该FILE结构包括:用于实际I/O的文件描述符,指向该流缓冲区的指针,缓冲区的长度,当前缓冲区的字符,以及出错标志等等。
FILE结构定义在/usr/include/stdio.h中。
_IO_FILE结构定义在/usr/include/libio.h中。
本章主要内容总结如下图: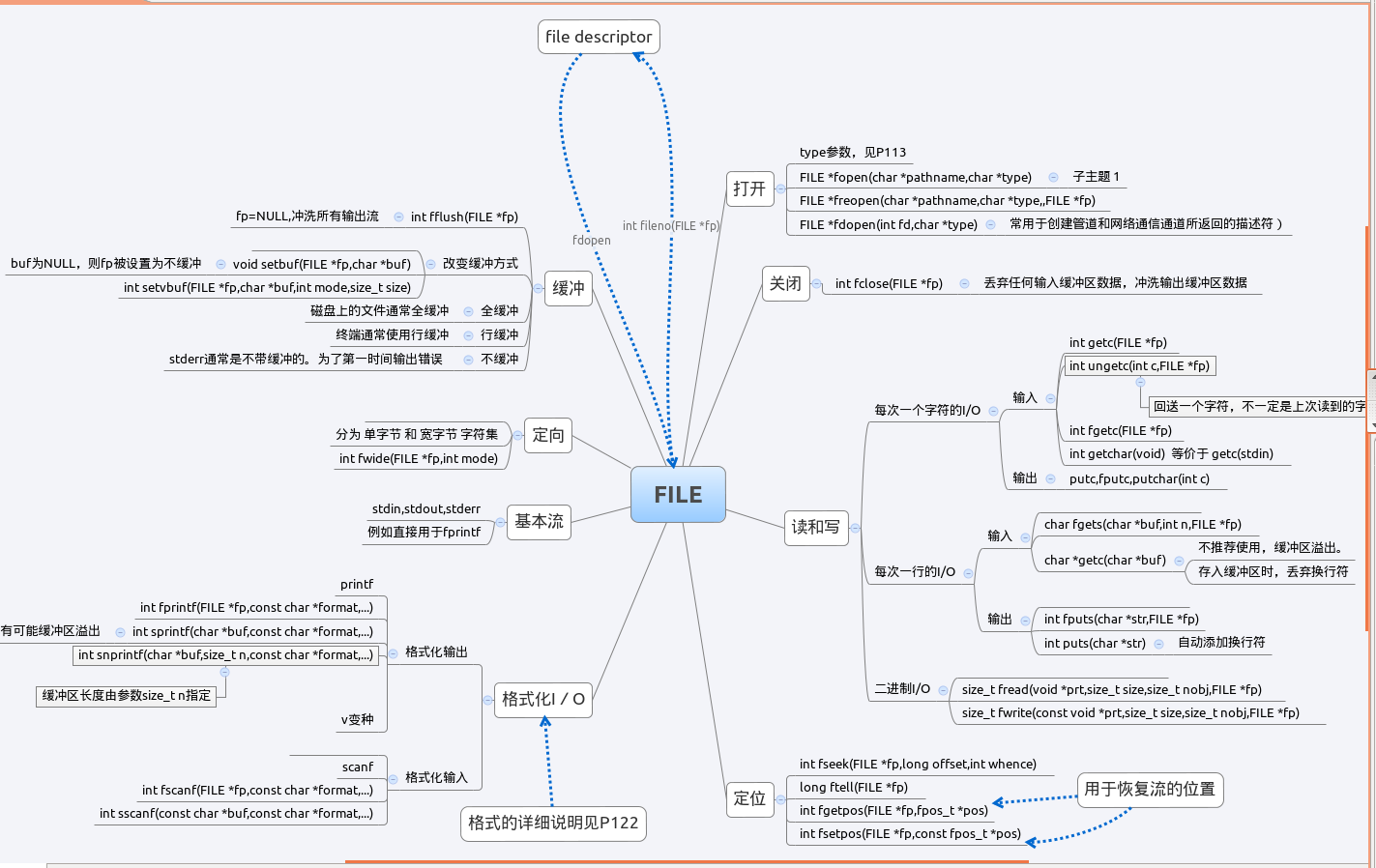
流和FILE对象
文件I/O函数都是针对文件描述符操作的。当打开一个文件时,则返回一个文件描述符,然后该文件描述符就用于后续的I/O操作。而对于标准I/O库,它们的操作则是围绕流(stream)进行的。当用标准I/O库打开或创建一个文件时,则使一个流与一个文件相关联。
对于ASCII字符集,一个字符用一个字节表示。对于Unicode字符集,一个字符可用多个字节表示。标准I/O文件流可用于单字节或多字节(“宽”)字符集。流的定向(stream’s orientation)决定了所读、写的字符是单字节还是多字节。当一个流最初被创建时,它并没有定向。
- 若在未定向的流上使用一个多字节I/O函数(见<wchar.h>),则将该流的定向设置为宽定向的。
- 若在未定向的流上使用一个单字节I/O函数,则将该流的定向设置为字节定向的。
只有两个函数可以改变流的定向:freopen函数清除一个流的定向;fwide函数设置流的定向。
根据mode参数的不同值,fwide函数执行不同的操作:
- 若
mode参数值为负,fwide将试图设置指定的流为字节定向。 - 若
mode参数值为正,fwide将试图设置指定的流为宽定向。 - 若
mode参数值为0,fwide将不设置流的定向,而是返回标识该流定向的值。
注意,fwide并不改变已定向流的定向。
当打开一个流时,标准I/O函数fopen返回一个指向FILE对象的指针。该对象通常是一个结构,它包含了标准I/O库为管理该流所需要的所有信息,包括:用于实际I/O的文件描述符、指向用于该流缓冲区的指针、缓冲区的长度、当前在缓冲区中的字符数以及出错标志等等。为引用一个流,需将FILE指针作为参数传递给每个标准I/O函数。FILE对象指针(类型为FILE *)也称为文件指针。
标准输入、标准输出和标准错误
对一个进程预定义了三个流,并且这三个流可以自动的被进程使用,它们是:标准输入、标准输出和标准错误。这些流引用的文件与文件描述符STDIN_FILENO、STDOUT_FILENO 和 STDERR_FILENO 所引用的文件相同。
这三个标准I/O流通过预定义文件指针stdin、stdout 和 stderr 加以引用。这三个文件指针同样定义在头文件<stdio.h>中。
缓冲
标准I/O库提供缓冲的目的是尽可能减少使用read和write调用的次数。它也对每个I/O流自动进行缓冲管理,从而避免了应用程序需要考虑这一点所带来的麻烦。不幸的是,标准I/O库最令人迷惑的也是它的缓冲。
标准I/O提供了三种类型的缓冲:
(1)全缓冲。这种情况下,在填满标准I/O缓冲区后才进行实际I/O操作。对于驻留在磁盘上的文件,通常是由标准I/O库实施全缓冲的。在一个流上执行第一次I/O操作时,相关标准I/O函数通常调用malloc获得需要使用的缓冲区。
(2)行缓冲。这种情况下,当在输入或输出中遇到换行符时,标准I/O库执行实际I/O操作。当流涉及一个终端时(例如标准输入和标准输出),通常使用行缓冲。
(3)不带缓冲。标准I/O库不对字符进行缓冲存储。调用标准I/O函数的每一次读写都会进行实际的I/O操作。标准错误流stderr通常是不带缓冲的,这就使得出错信息可以尽快显示出来,而不管它是否含有一个换行符。
术语 冲洗(flush)说明标准I/O缓冲区的写操作。缓冲区可由标准I/O例程自动冲洗(例如当填满一个缓冲区时),或者可以调用fflush冲洗一个流。值得注意的是,在UNIX环境中,flush有两种意思:在标准I/O库方面,flush(冲洗)表示将缓冲区中的内容写到磁盘上(该缓冲区可能未填满);而在终端驱动程序方面(例如tcflush函数),flush(刷清)表示丢弃已存储在缓冲区中的数据。
对于行缓冲,有两个限制。
第一,因为标准I/O库用来收集每一行字符的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有写入一个换行符,也进行I/O操作。
第二,任何时候只要通过标准I/O库从(a)一个不带缓冲的流,或者(b)一个行缓冲的流(它需要向内核请求数据)输入数据,则会冲洗所有行缓冲输出流。
对任何一个给定的流,可调用下列两个函数中的任一个更改缓冲类型:
这些函数一定要在流已被打开后调用(这是十分明显的,因为每个函数都要求一个有效的文件指针作为它的第一个参数),而且也应该在对该流执行任何一个其他操作之前调用。
可以使用setbuf函数打开或关闭缓冲机制。为了带缓冲进行I/O,参数buf必须指向一个长度为BUFSIZ的缓冲区(该常量定义在<stdio.h>中)。通常在此之后该流就是全缓冲的,但如果该流与一个终端设备关联,那么某些系统也可将其设置为行缓冲。为了关闭缓冲,将buf设置为NULL。
使用setvbuf,可以精确的指定所需的缓冲类型。这是用mode参数实现的:
| mode | Description |
|---|---|
_IOFBF |
全缓冲(fully buffered) |
_IOLBF |
行缓冲(line buffered) |
_IONBF |
不带缓冲(unbuffered) |
- 如果指定一个不带缓冲的流,则忽略
buf和size参数。 - 如果指定全缓冲或行缓冲,则
buf和size可选择地指定一个缓冲区及其长度。 - 如果该流是带缓冲的,而
buf是NULL,则标准I/O库将自动的为该流分配适当长度的缓冲区。适当长度指的是由常量BUFSIZ所指定的值。
某些C函数库实现使用
stat结构中的成员st_blksize所指定的值决定最佳I/O缓冲区长度,GNU C函数库就使用这种方法。
如果在一个函数内分配一个自动变量类型的标准I/O缓冲区,则从该函数返回之前,必须关闭流(因为函数返回后,自动变量内存被自动释放)。另外,有些实现将缓冲区的一部分用于存放它自己的管理操作信息,所以可以存放在缓冲区中的实际数据字节数少于size。一般而言,应由系统选择缓冲区的长度,并自动分配缓冲区,在这种情况下关闭该流时,标准I/O库将自动释放缓冲区。
在任何时候,都可以强制冲洗一个流。
此函数使所指定流中所有未写的数据都被传送至内核。作为一个特例,如若fp为NULL,则此函数将导致所有输出流被冲洗。
流(stream) I/O
打开和关闭流
下列三个函数打开一个标准I/O流:
这三个函数的区别是:
(1)fopen打开一个指定的文件。
(2)freopen在一个指定的流上打开一个指定的文件。
- 如果该流已经打开,则先关闭该流;
- 如果该流已经定向,则
freopen清除该定向。
此函数一般用于将一个指定的文件打开为一个预定义的流:标准输入、标准输出和标准错误。
(3)fdopen获取一个现有的文件描述符,并关联一个标准的I/O流到该文件描述符。此函数常用于由创建管道或网络通信通道的函数返回的描述符(可由open、dup、dup2、fcntl、pipe、socket、socketpair或accept函数获得),因为这些特殊类型的文件不能用标准I/Ofopen函数打开,所以必须先调用设备专用函数获得一个文件描述符,然后用fdopen关联一个标准I/O流到该描述符。
fopen和freopen是ISO C的组成部分,而fdopen是POSIX.1的组成部分,因为ISO C并不涉及文件描述符。
type参数指定对I/O流的读、写方式,ISO C规定type参数有15种不同的值,如下表5-2所示。
Figure 5.2. The type argument for opening a standard I/O stream
| type | Description |
|---|---|
| r or rb | open for reading |
| w or wb | truncate to 0 length or create for writing |
| a or ab | append; open for writing at end of file, or create for writing |
| r+ or r+b or rb+ | open for reading and writing |
| w+ or w+b or wb+ | truncate to 0 length or create for reading and writing |
| a+ or a+b or ab+ | open or create for reading and writing at end of file |
使用字符 b 作为type的一部分,这使得标准I/O系统可以区分文本文件和二进制文件。因为UNIX内核并不区分这两种文件,所以在UNIX系统环境下指定字符 b 作为type的一部分,实际上并无作用。
对于fdopen,type参数的意义稍有区别。因为该描述符已被打开,所以fdopen为写而打开(opening for write)并不截短(truncate)该文件。另外,标准I/O添写方式(append mode)也不能用于创建该文件(如果一个描述符引用一个文件,则该文件一定已经存在)。
当用添写方式打开一个文件,则每次写都将数据写到文件的当前尾端处。如果有多个进程用标准I/O添写方式打开同一个文件,来自每个进程的数据都将正确地被写到文件中。
当以读和写方式打开一个文件时(type中的 + 符号),具有下列限制:
- 如果中间没有
fflush、fseek、fsetpos或rewind,则在输出的后面不能直接跟随输入。 - 如果中间没有
fseek、fsetpos或rewind,或者一个输入操作没有到达文件尾端,则在输入操作之后不能直接跟随输出。
在指定 w 或 a 方式创建一个新文件时,无法说明该文件的访问权限位(open函数和creat函数则能做到这一点)。
除非流引用终端设备,否则按系统默认的情况,流被打开时是全缓冲的。若流引用终端设备,则该流是行缓冲的。流一旦被打开,在对该流执行任何操作之前,如果希望,则可以使用前述的 setbuf 和 setvbuf 改变缓冲的类型。
调用fclose关闭一个打开的流。
在该文件被关闭之前,冲洗缓冲区中的输出数据,丢弃缓冲区中的输入数据。如果标准I/O库已经为该流自动分配了一个缓冲区,则释放该缓冲区。
当一个进程正常终止时(直接调用exit函数,或从main函数返回),则所有未写缓冲数据的标准I/O流都会被冲洗,所有打开的标准I/O流都会被关闭。
读和写流
一旦打开了流,则可在三种不同类型的非格式化I/O中进行选择,对其进行读、写操作:
- 每次一个字符 I/O(Character-at-a-time I/O)。一次读或写一个字符,如果流是带缓冲的,则标准I/O函数会处理所有缓冲。
- 每次一行 I/O(Line-at-a-time I/O)。如果想要一次读或写一行,则使用
fgets和fputs。每行都以一个换行符终止。 - 直接 I/O(Direct I/O)。
fread和fwrite函数支持这种类型的I/O。每次I/O操作读或写某种数量的对象,而每个对象具有指定的长度。这两个函数常用于从二进制文件中每次读或写一个结构。
直接I/O这个术语来自ISO C标准,有时也称为二进制I/O、一次一个对象I/O、面向记录的I/O或面向结构的I/O。
每次一个字符 I/O
1、输入函数
以下三个函数可用于一次读入一个字符:
函数getchar等价于getc(stdin)。前两个函数的区别是,getc可被实现为宏,而fgetc则不能实现为宏。这意味着:
getc的参数不应当是具有副作用的表达式。- 因为
fgetc一定是一个函数,所以可以得到其地址。这就允许将fgetc的地址作为一个参数传送给另一个函数。 - 调用
fgetc所需时间可能长于调用getc,因为调用函数通常所需的时间长于调用宏。
这三个函数在返回下一个字符时,会将其unsigned char类型转换为int类型。声明为不带符号的理由是,如果最高位为1也不会使返回值为负。要求整型返回值的理由是,这样就可以返回所有可能的字符值,再加上一个已出错或已到达文件尾端的指示值。在<stdio.h>中的常量EOF被要求是一个负值,其值经常是-1。这就意味着不能将这三个函数的返回值存放在一个字符变量中,以后还要将这些函数的返回值与常量EOF相比较。
注意,不管是出错还是到达文件尾端,这三个函数都返回同样的值EOF。为了区分这两种不同的情况,必须调用ferror或feof:
在大多数实现中,为每个流在FILE对象中维持两个标志:
- 出错标志。
- 文件结束标志
调用clearerr则清除这两个标志。
从流中读取数据以后,可以调用ungetc将字符再压送回流中。
压送回流中的字符以后又可以从流中读出,但读出字符的顺序与压送回的顺序相反。虽然ISO C允许实现支持任何次数的回送,但是它要求实现提供一次只回送一个字符,不能一次回送多个字符。
回送的字符不必一定是上一次读到的字符。不能回送EOF(EOF并非文件中的数据,而是文件到达尾端时的指示值),但是当已经到达文件尾端时,仍可以回送一个字符。下次读将返回该字符,再次读则返回EOF。之所以能这样做的原因是,一次成功的ungetc调用会清除该流的文件结束标志。
Pushback is often used when we’re reading an input stream and breaking the input into words or tokens of some form.
当正在读一个输入流,并进行某种形式的分字或分记号操作时,会经常用到回送字符的操作。
有时需要先看一看下一个字符,以决定如何处理当前字符。因此需要方便地将刚查看的字符送回,以便下一次调用getc时返回该字符。如果标准I/O库不提供回送功能,就需要将该字符存放到一个变量中,并设置一个标志以便判别在下一次需要一个字符时是调用getc,还是从变量中读取。
用
ungetc压送回字符时,并没有将它们写到文件中或设备上,只是将它们写回标准I/O库的流缓冲区。
2、输出函数
对应于上面所述的每个输入函数,都有一个输出函数:
与输入函数一样,putchar(c)等效于putc(c, stdout),putc可实现为宏,而fputc则不能实现为宏。
每次一行 I/O
下面两个函数提供每次输入一行的功能:
这两个函数都指定了缓冲区的地址,并将读入的行送入其中。gets从标准输入读,而fgets则从指定的流读。
对于fgets,必须指定缓冲区的长度n。此函数从流中读取字符,直到遇到一个换行符(包含该换行符)为止,但是不超过n-1个字符。读入的字符被送入缓冲区,该缓冲区以null字符结尾。如果该行(包括最后的换行符)的字符超过n-1,则fgets返回一个不完整的行,但缓冲区总会以null字符结尾,对fgets的下一次调用会继续读取该行剩下的数据。
gets是一个不推荐使用的函数。其问题在于调用者在使用gets时不能指定缓冲区的长度,这样就可能造成缓冲区溢出(如果该行长于缓冲区长度),写到缓冲区之后的存储空间,从而产生不可预料的后果。gets与fgets的另一个区别是,gets并不将换行符存入缓冲区中。
即使ISO C要求实现提供gets,但请使用fgets,而不要使用gets。
fputs 和 puts 提供每次输出一行的功能:
函数fputs将一个以null字符终止的字符串写到指定的流,尾端的终止符null不写出。注意,这并不一定是每次输出一行,因为它并不要求在null字符之前一定是换行符。通常,在null字符之前是一个换行符,但并不要求总是如此。
puts将一个以null字符终止的字符串写到标准输出,终止符不写出。但是,puts然后又将一个换行符写到标准输出。
puts并不像它所对应的gets那样不安全,但还是要避免使用它,以免需要记住它在最后是否添加了一个换行符。如果总是使用fgets和fputs,那么就会熟知在每行终止处必须自己处理换行符。
二进制 I/O
二进制 I/O,通常是一次读或写一整个结构体。下列两个函数执行二进制I/O操作:
这些函数的两种常见的用法:
(1)读或写一个二进制数组。例如,将一个浮点数组的第2~5个元素写至一个文件上,可编写如下程序:
其中,指定size为每个数组元素的长度,nobj为欲写的元素数。
(2)读或写一个结构。例如,可编写如下程序:
其中,指定size为结构的长度,nobj为1(要写的对象数)。
将这两个例子结合起来就可读或写一个结构数组。为了做到这点,size应当是该结构的sizeof,nobj应是该数组中的元素个数。
fread和fwrite返回读或写的对象数。
- 对于读,如果出错或到达文件尾端,则返回值可以小于
nobj。这种情况下,应调用ferror或feof以判断究竟属于哪一种情况。 - 对于写,如果返回值小于所要求的
nobj,则出错。
使用二进制I/O的基本问题是,它只能用于读在同一系统上已写的数据。其原因是:
(1)在一个结构中,同一成员的偏移量可能因编译器和系统而异(不同的对齐要求)。
(2)用来存储多字节整数和浮点值的二进制格式在不同的机器体系结构间也可能不同。