在Linux内核中,hlist(哈希链表)使用非常广泛,本文将对其数据结构和核心函数进行分析。
和hlist相关的数据结构有两个
- hlist_head
- hlist_node1234567struct hlist_head {struct hlist_node *first;};struct hlist_node {struct hlist_node *next, **pprev;};
顾名思义,hlist_head表示哈希表的头结点。哈希表中每一个 entry (hlist_head) 所对应的都是一个链表(hlist),该链表的结点由hlist_node表示。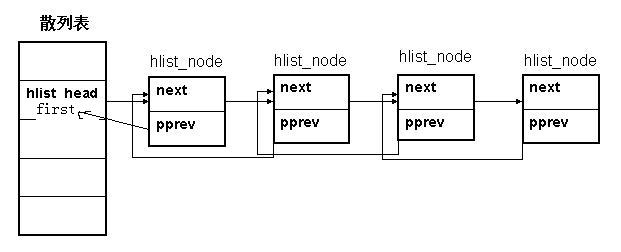
hlist_head 结构体只有一个域,即first。first指针指向该 hlist 链表的第一个节点。
hlist_node结构体有两个域,next和pprev。 next指针很容易理解,它指向下个hlist_node结点,倘若该节点是链表的最后一个节点,next指向NULL。
pprev是一个二级指针,为什么我们需要这样一个指针呢?它的好处是什么?
在回答这个问题之前,我们先研究另一个问题:为什么散列表的实现需要两个不同的数据结构?
散列表的目的是为了方便快速的查找,所以散列表通常是一个比较大的数组,否则“冲突”的概率会非常大,这样也就失去了散列表的意义。如何做到既能维护一张大表,又能不使用过多的内存呢?这就只能从数据结构上下功夫了。所以对于散列表的每个entry,它的结构体中只存放一个指针,解决了占用空间的问题。现在又出现了另一个问题:数据结构不一致。显然,如果hlist_node采用传统的next, prev指针,对于第一个节点和后面其他节点的处理会不一致。这样并不优雅,而且效率上也有损失。
hlist_node巧妙地将pprev指向上一个节点的next指针的地址,由于hlist_head和hlist_node指向的下一个节点的指针类型相同,这样就解决了通用性!
下面我们再来看一看hlist_node这样设计之后,插入、删除这些基本操作会有什么不一样。
__hlist_del用于删除节点n。
首先获取n的下一个节点next,n->pprev指向n的前一个节点的next指针的地址,这样*pprev就代表n前一个节点的下一个节点(现在即n本身),第三行代码*pprev=next;就将n的前一个节点和下一个节点关联起来了。至此,n 节点的前一个节点的关联工作就完成了,现在再来完成后一个节点的关联工作。如果n是链表的最后一个节点,那么n->next即为空,则无需任何操作,否则,next->pprev = pprev。
给链表增加一个节点需要考虑两个条件:
- 链表首节点
- 链表普通节点
|
|
首先讨论条件1:first = h->first;获取当前链表的首个节点;n->next = fist; 将n作为链表的首个节点,让first往后靠;
先来看最后一行n->pprev = &h->first;将n的pprev指向hlist_head的first指针,至此关于节点n的关联工作就做完了。
再来看倒数第二行h->first = n;将节点h的关联工作做完;
最后我们再来看原先的第一个节点的关联工作,对于它来说,仅仅需要更新一下pprev的关联信息:first->pprev = &n->next;
接下来讨论条件2,这里也包括两种情况:
a) 插在当前节点的前面
b) 插在当前节点的后面
|
|
先讨论情况 a):将节点n插到next之前(n是新插入的节点)
还是一个一个节点的搞定(一共三个节点),先搞定节点n,
|
|
将next的pprev赋值给n->pprev,n取代next的位置,
|
|
将next作为n的下一个节点,至此节点n的关联动作完成。
|
|
next的关联动作完成。
|
|
n->pprev表示n的前一个节点的next指针,*(n->pprev)则表示n的前一个节点next指针所指向下一个节点的内容,这里将n赋值给它,正好完成它的关联工作。
|
|
再来看情况 b):将结点next插入到n之后(next是新插入的节点)
具体步骤就不分析了,应该也很容易。
下面我还要介绍一个函数:
这个函数的目的是判断该节点是否已经存在hash表中。这里处理得很巧妙,判断指向前一个节点的next指针的地址是否为空。
其他接口
初始化
|
|
链表判空
|
|
节点删除
|
|
链表遍历
hlist_entry
|
|
hlist_for_each
|
|
hlist_for_each_entry
|
|