原文:page-cache-the-affair-between-memory-and-files
作者:Gustavo Duarte
译文:文件与内存的桥梁:Page Cache
翻译:fleurer
前面我们观察了内核为用户进程管理虚拟内存的方法,简单起见,一时忽略了文件和IO。本文则着重讨论下这块,说说文件和内存之间的暧昧关系,及其对性能的影响。
关于文件,有两个严肃的问题需要考虑。首先是与内存相比,硬件设备往往是发指的慢,其寻址尤然;其次是某文件只应装入物理内存一次,其内容可为不同 程序所共享。比如用Process Explorer观查Windows进程的话可以发现,有大约15MB的公用DLL在所有进程中都有装载。想下,我的Windows现在有100个进程, 要是没有共享机制,光这些公共DLL就得占去1.5GB的物理内存,显然不靠谱。同样Linux下也是几乎每个程序也都得用到ld.so和libc,一些常用的共享库也是不可或缺的。
幸甚,上述两个问题能够一举解决:Page Cache,即内核以页为单位缓存文件的机制。拿例子说话,我们编写一个Linux程序render,它打开scene.dat文件,每次读取512字节,将其储存于堆里。第一次读取大约即这样: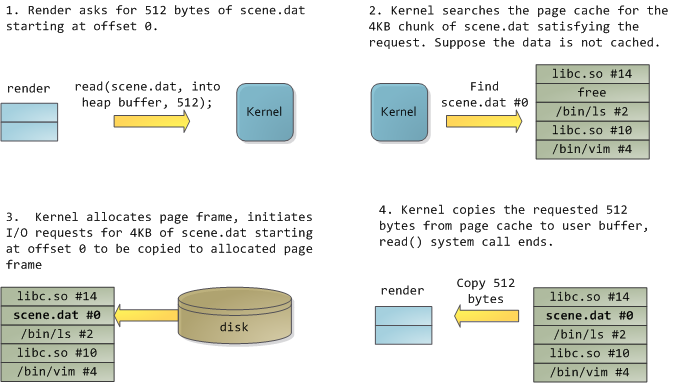
12kb读取完毕,它的堆和相关的页框大约这样: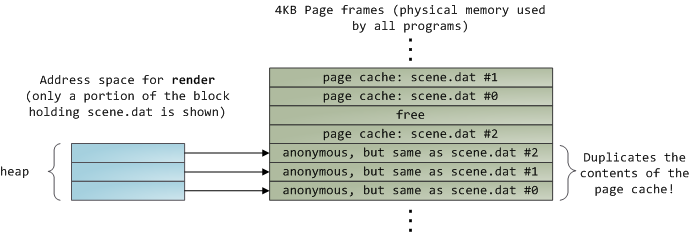
比较明显了,不过还有些地方待挖掘。首先,这个程序只是使用普通的read调用,即已有三个4kb的页作为Page Cache来存放scene.dat。可能难以置信,但事实如此:任何普通文件的读写都必须经过Page Cache。x86体系结构的Linux将文件看作是n个4kb的块相连而成的序列,即使仅仅读取一个字节,也不得不读入整个4kb大小的块到Page Cache。文件的读写往往不是几个字节就罢,这样设定有助于提升磁盘的吞吐量。每个Page Cache对应文件中的一个4kb块,并一个唯一的编号。Windows中的等价物是256kb的视图(view)。
然而杯具是,普通的一个read之后,内核还要把Page Cache里的内容额外拷贝到用户态的缓冲区,既费CPU时间又污染CPU缓存,还浪费物理内存。如上图所示,scene.dat里同样的内容被储存在了 两个地方,而且每个该程序的实例都会如此重复,进一步白白浪费时间浪费空间。我们缓解了磁盘延时这一重镇的危险,却尽失其它城池。于是下一个方案呼之欲 出,即文件映射(Memory-mapped files)。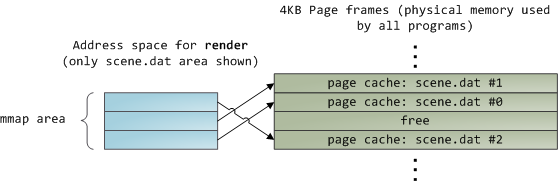
使用文件映射时,内核会把程序的虚拟页面直接映射到Page Cache上。这一来性能就燃了:《Windows System Programming》有提及说这样比起普通的read方式,性能提升30%。《Unix环境高级编程》里对Linux和Solaris的性能测试的结 果也与之相似。情景合适的话,还可以为程序节省大量的物理内存。
谈及性能,评测至上。而内存映射凭其优良的性能,值得为每个程序员所了解。API也很漂亮,一字节一字节的读内存即访问文件,甚至不用纠结可读性与 性能的trade off。*nix上有mmap,windows有CreateFileMapping,还有其它高级语言的各种封装,都不妨一试,留意下你的地址空间。在 映射文件的时候,其内容并不是一次性装入内存,而是基于Page Fault的请求调页。取一个物理页存放其内容,然后fault handler将这个虚拟页映射到Page Cache。这是缓存之前的第一次读取。
提个问题:在最后一个例子程序在执行结束后,Page Cache里的内容会不会释放?可能直觉该如此,但实际上这样不好。想想,我们经常会在某程序里打开某个文件,它退出了之后第二个程序还得用它—— Page Cache必须对此有所考虑。比如需要跑那个例子程序一星期,一直缓存着scene.dat不就赚大了。既如此,那Page Cache的内容该在什么时候释放呢?永远记着磁盘的读取速度得比内存慢五个量级,能命中Page Cache自是多多益善。所以只要还有空闲的物理内存,内核就总是拿来做缓存使。Page Cache不是某个进程的私有财产,它是为整个系统所共享的资源。这就是为啥内核缓存总是不到极限不休——绝不是因为系统烂吃内存,毕竟物理内存闲着也是 闲着,缓存不嫌多。这是个很好的做法。
Page Cache架构下的write()调用就只是将数据写入Page Cache再把它标记为dirty,而磁盘IO通常并不立即执行,程序也就无需为磁盘而阻塞。这样的不足就是机器一旦意外崩溃,就可能会丢失部分数据。因 此对完整性要求高的文件(比如数据库事务的log)通常会在写入后调用fsync()(唔,还有磁盘驱动器缓存需要纠结)。read通常是阻塞等待数据读 取就绪。为减少这里的阻塞,内核会一次性多读几个页,预先缓存起来,即“贪婪读取”(Eager Loading)。我们可以调整贪婪读取的参数(参见madvise(),readahead(),或windows的cache hints),告诉内核我们读取起来是顺序还是随机。Linux会为内存映射的文件执行预读取(read-ahead),Windows则不清楚。跳过 Page Cache也是可以的,数据库经常需要这样:Linux可以O_DIRECT,Windows可以NO_BUFFERING。
文件的映射也可以设为私有,即私有映射中的内存读写不会影响到磁盘中文件的内容,也不会对影响到其它进程中的数据,而不像共享映射那样二者皆同步其 变化。内核在私有映射的实现上应用了写时复制机制。如下面的例子里,render和render3d两个程序都私有映射了同一个文件scene.dat, 随后render修改了一下文件映射的虚拟内存: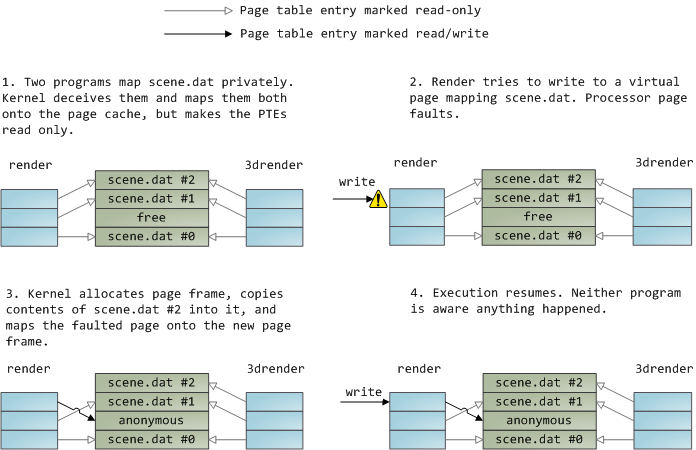
如上这个页表项是“只读”并不意味着这个映射是只读的。这就是内核用以实现写时复制的小trick,共享物理页,不到万不得已决不复制——这个“万 不得已”由x86把关而不是内核。搞明白所谓“私有映射”仅仅是针对“更改“就好理解了。这样设计的一个结果是:在对私有映射来的页面进行修改前,其他程 序对它的修改都是可见的;一旦经过写时复制,其他程序对它的修改就不可见了。与之相对,共享映射仅仅把page cache映射到位即可,对它的修改对其它进程皆可见,文件在磁盘中也一并修改。若是只读映射就免了写时复制,Page Fault时直接一个segmentation fault。
动态库也是通过文件映射装入程序的地址空间,就是普通的私有文件映射,并无特殊之处。如下是同一例子程序的两个实例,其地址空间和物理内存的样子足已囊括本文出现的很多概念: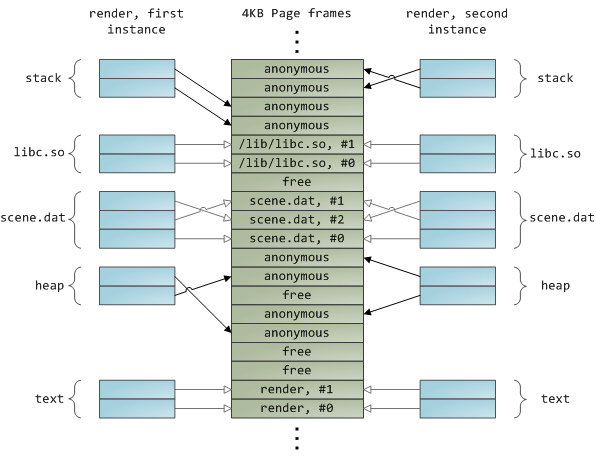
以上,内存三部曲已告一段落。希望对大家有帮助,对操作系统的相关概念有个感性认识就好。下周再一篇post说说内存的分配图,也该换换话题了,比如web2.0八卦什么的 :)